



The Difference Between an ODBMS and a RDBMS
To understand the differences between the traditional Relational Database Management Systems (RDBMS) and the modern Object-Orientated Database Management Systems (ODBMS), we need to look at the underlining structures that each type of Database Management System (DBMS) is built upon.
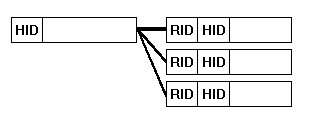
Firstly, the traditional database management systems (RDBMS) were designed with two distinct sections - the table file containing the records and the standard B+-Tree index file, and as part of this table design the data records are identified within the system by their file locations. This limited structure gave the RDBMS a problem when the records within the database were moved, for example when a variable length record out grew the available space, or when the data file was compacted, and either way their file location had to be changed. This problem prevented database designer's from using the record location to refer to each individual record within the database schemas and had to subsequently resort to using a Record Identifier (RID) and a B+-Tree index to locate each record. This patchy solution creates the relational relationship as depicted in the diagram below where the records are related to their header record.
In the relational scenario, the header record would be given a Header Identifier (HID) and each record containing a line would be given a Record Identifier. This design would then use an index on the fields <HID,RID>; or in some circumstances a very slow join operation to draw the relation out of the database.
Secondly, in an object database there are now three separate sections, the data records (the objects), a static hash index as well as the traditional B+-Tree and S-Tree indexes. Within the table file exists a hash index with true order one efficiency (O(1)), that converts an object identifier into its corresponding file position. This allows objects to be referred directly by their ObjectID (OID) and this identifier is guaranteed by the system to be unique and persistent – even when the data is moved within the file.
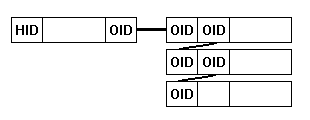
Now having a fundamental understanding between the underline structural differences of an ODBMS and a RDBMS, we can see some useful applications for this technology. The ability to refer directly to an object allows a new design when representing the relationship between data. As well as the relational model, there are two new designs, first is to use a linked list. In this design the first object is pointed to by the header object by its OID , then each line has an OID to point to the next object within the list (is design is also referred to as a bag). Using the hash index gives true O(1) efficiency when retrieving the relation out if the database, as there is no join operation required.
In this design there need not be any extra B<sup>+</sup>-Tree indexes to be maintained.
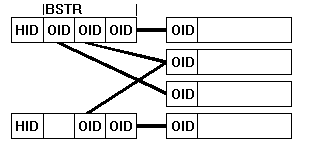
In the next design, ObjectDatabase++ uses its native variable length binary string type (CODBPP::BSTR) to store each of the OIDs of each line of the relation. The BSTR is a variable field that can hold as many OIDs as required. This newer design is beneficial over the traditional on as it allows for situations when not all the line objects needed to be read in, or when one or more line objects are used by multiple header objects, providing for m:n relationships.
ObjectDatabase++ Complex Objects
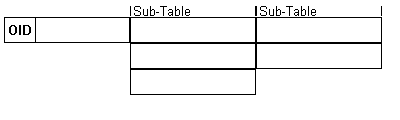
For maximum efficiently, ObjectDatabase++ provides a variable field type CODBPP::SUB_TABLE. With this it is possible to store all related items of an object within one variable length field, this will reduce the total amount of read and lock operations per transaction and should be considered when designing your object database. And with the unique multi-entry indexes that ObjectDatabase++ provides, information stored within the CODBPP::SUB_TABLE are just as accessible as information stored in related tables.
It has been our experience when designing database schemas, to try and reduce the total amount of tables. When multiple lines of data are stored and only related back to jost one object, then creating a more complex object with CODBPP::SUB_TABLE is preferred. Breaking up objects in a similar method to a related database only when more then one object refers to the itemised record - i.e. an m:n relationship.
Try today by freely downloading ObjectDatabase++ and its GUI Editor.
Also For more information about ODBMSs please feel free to vists this website.
Listen All
Comments (0)
